こんにちは、ネットエージェント株式会社の松本です。今回はフォレンジック分野におけるエントロピーについて話させていただこうと思います。
-----
最近、フォレンジックの分野でもエントロピーという言葉を耳にすることが多くなってきた。エントロピーは本家CEIC2010で研究成果がプレゼンされ、フォレンジック調査ツールのEnCaseによって正式にサポートされるなど、フォレンジックの新しい技術として注目されつつある。また、日本でも株式会社Ji2が実施した技術セミナーの中で、近似ファイルの検出方法のひとつとして紹介されている。
今回は、Guidance Software社の公開しているホワイトペーパー「Utilizing Entropy to Identify Undetected Malware」を参考に、フォレンジック分野におけるエントロピーについて簡単な紹介をしたいと思う。
エントロピー (entropy) は、もともとは物質や熱の拡散の程度を表す熱力学上のパラメーターであるが、その概念は情報理論の分野にも応用されている。ここで紹介するのは後者の情報理論、とりわけフォレンジック調査で情報解析の手段として最近注目されつつあるエントロピーという概念である。
情報理論におけるエントロピーとは、ウィキペディアを引用すると「あるできごと(事象)が起きた際、それがどれほど起こりにくいかをあらわす尺度」と説明できる。電子データは1バイト=8ビットで構成される。それぞれのビットは0か1どちらかの値をとるため、1バイトのデータは2^8つまり256通りで表現される。

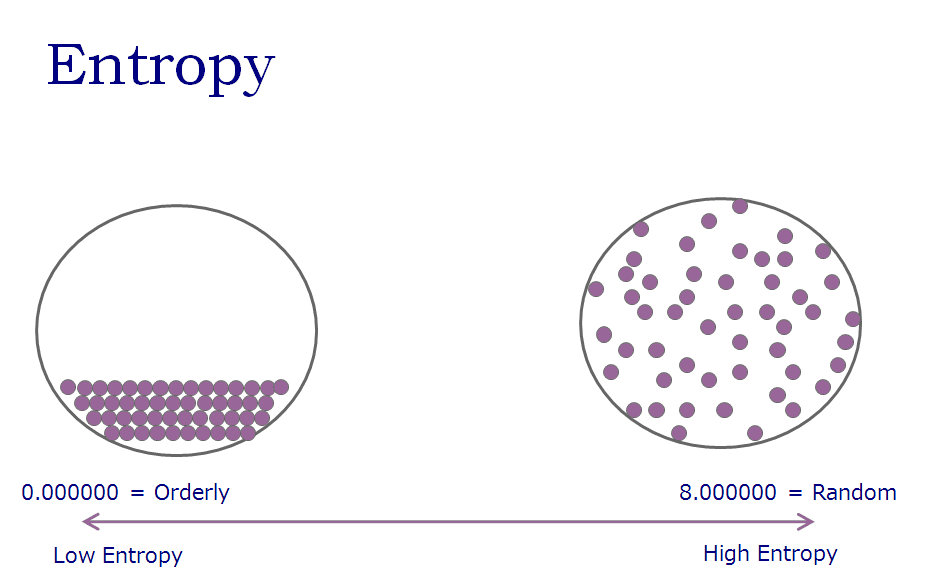 情報理論としてのエントロピーは、電子データを256通りで表現されるバイトの集合とみなす。そして、そのバイト集合に偏りがある場合は、電子データが規則性のある状態、逆に偏りが存在しない場合はランダムな状態とみなす。そして、計算された電子データの"ランダムさ"は、「エントロピー値」という絶対値として表現される。エントロピー値は0から8の実数値をとり、低いほど対象データに規則性があり、高いほど完全なランダムに近い状態であることを表す。
情報理論としてのエントロピーは、電子データを256通りで表現されるバイトの集合とみなす。そして、そのバイト集合に偏りがある場合は、電子データが規則性のある状態、逆に偏りが存在しない場合はランダムな状態とみなす。そして、計算された電子データの"ランダムさ"は、「エントロピー値」という絶対値として表現される。エントロピー値は0から8の実数値をとり、低いほど対象データに規則性があり、高いほど完全なランダムに近い状態であることを表す。
電子データの状態をエントロピー値で表現することにより、ストレージに存在する大量の情報を分類したり、特定データ間での近似を検証するのに役立つ。ご存知の通り、電子データは内容を閲覧するだけでも変化してしまう可能性がある。また、オリジナルデータに対し、意図的に変更を加えて検知を逃れるタイプのマルウェアやアンチフォレンジック手法が存在するため、オリジナルファイルと複製ファイルの近似を客観かつ定量的に表現することは、フォレンジック調査にとって非常に大きな意味がある。
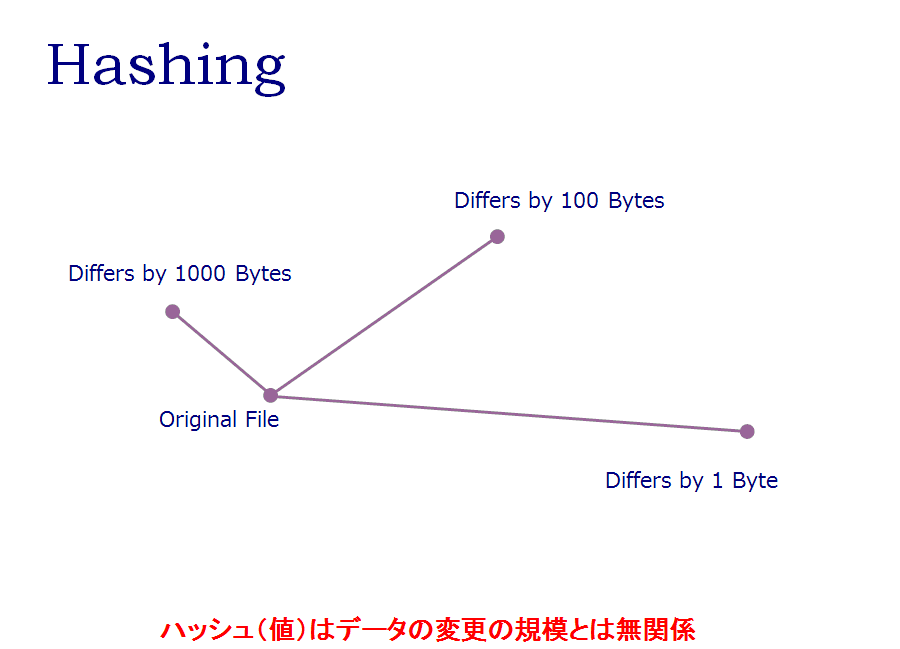 エントロピーはデータの状態を表現しており、対象データの一部を変更した場合、オリジナルデータとエントロピー値の変化の量には相関関係が存在する。これに対して、フォレンジックでデータの識別に用いられるMDやSHAなどのHashingと呼ばれる方法では、データとハッシュ値の変化量に相関関係が存在しないため、オリジナルファイルにどの程度の変更が加わったかに関して、客観的な判断を加えることはできない。
エントロピーはデータの状態を表現しており、対象データの一部を変更した場合、オリジナルデータとエントロピー値の変化の量には相関関係が存在する。これに対して、フォレンジックでデータの識別に用いられるMDやSHAなどのHashingと呼ばれる方法では、データとハッシュ値の変化量に相関関係が存在しないため、オリジナルファイルにどの程度の変更が加わったかに関して、客観的な判断を加えることはできない。
この性質は、計算されたハッシュ値への攻撃に対して強いという意味においてHashingの長所でもあるが、ファイルの近似の検証という点においては、エントロピーに軍配が上がる。また、Hashingと比べ、計算コストが低くてすむため、大量のデータをすばやく検証するのにもエントロピーは向いている。
注意すべき点として、エントロピー値は0から8の狭い幅で表現されるため、ファイルタイプによって値に傾向が現れてくる。テキストファイルのような、規則性の存在しやすいデータは低エントロピーに、逆に圧縮や暗号化ファイルのような、複雑で規則性の少ないデータは高いエントロピー値に偏る傾向がある。
また、エントロピー値自体はデータのランダム状態を表現するに過ぎないため、偶然的に、内容が全く異なるデータが近いエントロピー値をもつこともありうる。したがって、フォレンジック調査などでエントロピーを採用する場合、エントロピー値以外の観点とあわせて、近似度をたしかなものにする工夫が必要である。たとえば、Guidance Software社が政府機関等に提供しているEnCase Cybersecurity Entropy Near-Match Analyzerでは、下記の要素を総合的に判断して、近似度を確認するとともに結果の信頼性を上げている。
1. オリジナルファイルと対象ファイルのエントロピー値(とその差)
2. ファイルタイプ
3. オリジナルファイルと対象ファイルのファイルサイズ(とその差)
これは先述した、ファイル種別によってエントロピー値に偏りが生じること、そしてデータとエントロピー値の変化の量に相関関係が存在すること、この2つの性質を利用している。
今後エントロピーは様々な場面で応用されていくと思われる。既にメモリフォレンジックの分野でも株式会社Ji2の春山氏が自身のブログで発表している"Memory Forensic Toolkit"(2010年7月28日時点の最新バージョンは1.82)で、PsEntropyPEB, PsEntropyVADという形で実装されている(参照)。
筆者自身もエントロピーをメモリフォレンジックに用いて面白いことができないか、色々試しているところなので、何か成果が出ればこのブログで報告したいと思う。
2010/07/30 コース:元祖こってり
「元祖こってり」記事はネットエージェント旧ブログ[netagent-blog.jp]に掲載されていた記事であり、現在ネットエージェントに在籍していないライターの記事も含みます。